Using GPT from Python
Instead of chatting back and forth with ChatGPT in the browser, you can also use GPT (and other large language models) through programming languages like Python.
I recommend starting with the official OpenAI Python package. While you might have heard the hype around LangChain, LangChain is a rat’s nest of overly complex code and out-of-date documentation, so it’s probably better to skip for now.
ChatGPT is the web interface to the large language model named GPT. If you’re using the Python library, you’re talking directly to GPT.
Installing and setup
You install the OpenAI Python package using pip:
pip install openaiUsage
Let’s say we had a ChatGPT conversation about pickles:
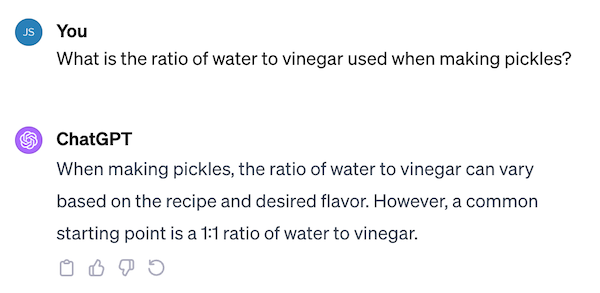
The Python version would look like the code below:
from openai import OpenAI
client = OpenAI(api_key="ABC123")
chat_completion = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are a helpful assistant.",
},
{
"role": "user",
"content": "What is the ratio of water to vinegar used when making pickles?",
}
],
model="gpt-3.5-turbo",
)
print(chat_completion.choices[0].message.content)
# When making pickles, the ratio of water to vinegar can vary based on the recipe and desired flavor. However, a common starting point is a 1:1 ratio of water to vinegar.You’ll need to get an API key from OpenAI so they can track your usage.
Talking to GPT is based on lists of messages.
Each message has a role and content. The different roles are:
system: the original setup instructions optionaluser: the person talking to the AI toolassistant: the AI tool itself
If you want to have a multi-round conversation with ChatGPT, you must send the entire conversation. It doesn’t remember the last time you called client.chat.completions.create.
Options
When you’re working with the OpenAI API, there are a few common options you might adjust.
Model selection
There are two major options of models you can use for text generation: GPT-3.5 or GPT-4. GPT-4 is better at reasoning tasks but is slower and costs more.
# Faster, cheaper, worse
client = OpenAI(api_key="ABC123", model_name='gpt-3.5-turbo')
# Better, slower, more expensive
client = OpenAI(api_key="ABC123", model_name='gpt-4')GPT-4 also has a larger context window, which is the amount of text it can pay attention to.
Text is counted “tokens” instead of characters or words, but an 8k token context window means a model can keep in mind around 10 pages of text at a time. As of this moment, GPT-4 can handle 8k tokens and GPT-3.5-turbo can handle 4k tokens, but it looks like some advanced versions can handle up to 128k tokens (~160 pages).
You can see current context window sizes for each model here.
Temperature
GPT is based around predicting the next word, but it doesn’t always pick the most likely one. By adding a little randomness it get a more creative-sounding output.
The temperature setting decides exactly how “random” it’s going to be. It can be set from 0-2, and the default is 0.7. Use 0 if you’d like your results to be (mostly) reproducible.
# Select the most probable word
chat_completion = client.chat.completions.create(
messages=messages,
model="gpt-3.5-turbo",
temperature=0.0
)
# Go a little crazy with it
chat_completion = client.chat.completions.create(
messages=messages,
model="gpt-3.5-turbo",
temperature=1.0
)Forcing JSON response
This is new! JSON mode allows you to demand JSON back from GPT.
You used to have to ask the model politely for JSON and even then sometimes it wouldn’t give it to you. Now it will!
from openai import OpenAI
import json
client = OpenAI(api_key="ABC123")
chat_completion = client.chat.completions.create(
response_format={ "type": "json_object" },
messages=[
{"role": "system", "content": "You are a helpful assistant designed to output JSON."},
{"role": "user", "content": "I went to the store with and bought beans and cabbage, but forgot the milk. Make a JSON object describing my shopping trip, with one key of 'purchased' and one of 'not_purchased'."}
],
model="gpt-3.5-turbo-1106",
)
data = json.loads(chat_completion.choices[0].message.content)
print(data)
# {'purchased': ['beans', 'cabbage'], 'not_purchased': ['milk']}